01 Mayıs 2025
Okuma Süresi: 10 dakika
Robots.txt Nedir? Neden Önemlidir? Nasıl Oluşturulur?
01 Mayıs 2025
Okuma Süresi: 10 dakika

Herkese merhaba.
Web sitenizin ön kapısında duran bir gardiyan düşünün. Bu gardiyan, arama motoru botlarını karşılıyor, onlara hangi odalara girebileceklerini ve hangilerinin yasak bölge olduğunu söylüyor.
İşte robots.txt dosyası, tam olarak bu görevi üstlenen dijital bir gardiyan gibidir. Bu küçük ama güçlü metin dosyası, web sitenizin arama motorları tarafından nasıl taranacağını ve indeksleneceğini belirlemede kritik bir rol oynar.
Bugün, robots.txt dosyasının ne olduğunu, neden bu kadar önemli olduğunu ve web siteniz için nasıl doğru şekilde oluşturabileceğinize değineceğim.
Hazırsanız, web sitenizin taranma ve indekslenme sürecini optimize etmenin sırlarını keşfetmeye başlayalım!
Robots.txt; bir web sitesinin crawl akışını farklı arama motoru botlarında yönetmek adına kullanılan ve birçok farklı komut (user-agent, disallow, allow, sitemap vb.) ile şekillendirilebilen bir dosya türü olarak tanımlanabilir.
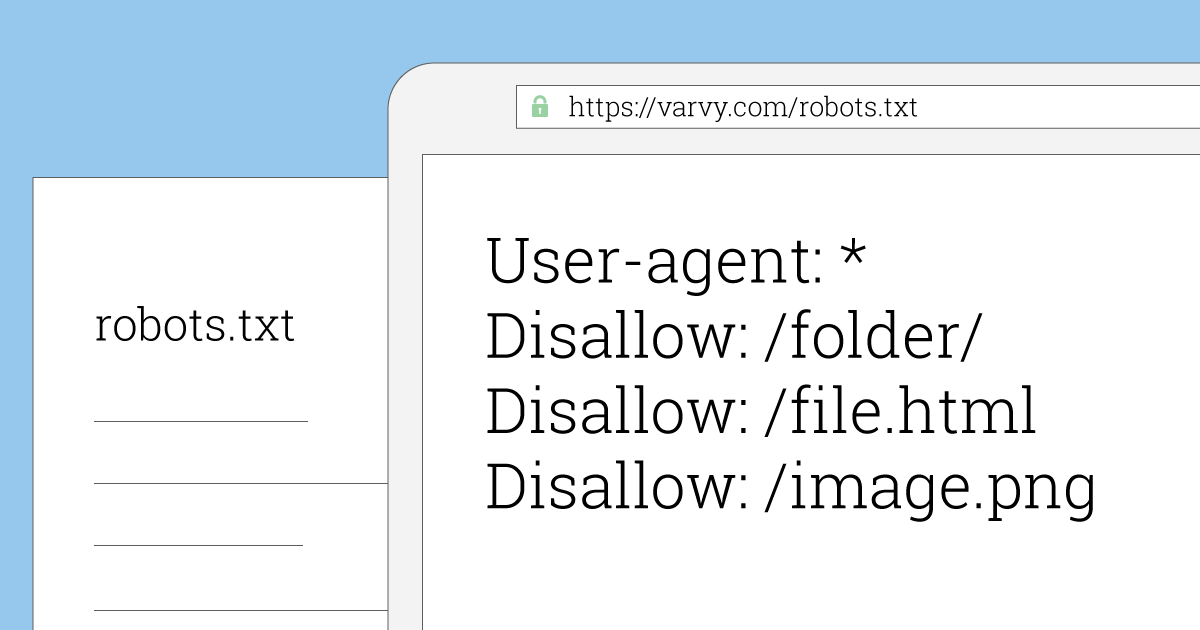
Crawl sürecine doğrudan temas etmesi itibariyle teknik SEO’nun önemli kavramlarından biri olan robots.txt’de doğru kurgu (hangi sayfaların taranmaması ya da taranması gerektiğinin ifadesi) hayli önemlidir.
Robots.txt’nin bir web sitesinin SEO görünürlüğü üzerindeki etkisi ve önemi doğrudan crawl budget (tarama bütçesi) ile ilgilidir.
Google’ın robots.txt guide’larında ve farklı kaynaklarda net bir şekilde ifade ettiği üzere arama motoru botları bir web sitesini ziyaret ettiğinde, crawl sürecini başlatmak adına robots.txt dosyasını inceler. (Robots.txt botlar için ilk seçenektir fakat olmaması durumunda diğer alternatifler ile herhangi bir engel yoksa web sayfaları crawl edilmeye devam eder.)
Dolayısıyla robots.txt dosyasında taranması ya da taranmaması gereken URL yapılarını doğru organize etmediğimiz takdirde SEO görünürlüğü hedeflediğimiz sayfalara arama motoru botlarının ulaşmasını engelleyebilir ya da web sitemiz akışı içerisinde yer almasına karşın görünürlük hedeflediğimiz ve değer üretmeyen web sayfalarının gereksiz bir şekilde crawl akışına dahil edilmesine zemin hazırlayarak crawl budget’ın anlamsız kullanımına neden olabiliriz.
Tüm bunlara baktığımızda robots.txt’nin arama motoru botlarının crawl sürecini organize etmesi ve crawl budget (tarama bütçesi) optimizasyonuna yardımcı olması itibariyle SEO’nun önemli kavramlarından biri olduğunu söyleyebiliriz.
Robots.txt oluştururken kullanılabilecek birçok farklı komut vardır fakat bu komutlardan en önemlileri “User-Agent ve Disallow”dur.
User-Agent; robots.txt’de direktif vermek istediğimiz (disallow, allow) arama motoru botunu belirlerken ihtiyaç durumundan birden fazla kullanabileceğimiz bir komuttur.
Disallow; arama motoru botlarının crawl akışına dahil etmesini istemediğimiz sayfa ya da sayfaları ifade etmemize yarayan bir komuttur.
Senaryo 1
User-agent: *
Disallow: /blog/
komutları, arama motoru botu fark etmeksizin tüm botlar için /blog/ URL path’inin crawl akışına dahil edilmemesini ifade eder. Burada “*” işareti “tüm” anlamına gelir.
Senaryo 2
User-agent: *
Disallow: /
dersek bir web sitesinin tümünü crawl’a kapatabiliriz.
Senaryo 3
User-agent: Googlebot
Disallow: /kategori/
Disallow: /urun/deneme-urunu.html
Komutları, Googlebot user-agent’ı ile gelen bir crawl isteğinde /kategori/ URL path’inin ve /urun/deneme-urunu.html sayfasının crawl akışına dahil edilmemesini ifade eder.
Senaryo 4
User-agent: Googlebot
Allow: /deneme/
Disallow: /blog/
Not: Bu satıra kadar olan komutlar Googlebot User-agent’ı için geçerlidir çünkü bir alttaki satırde YandexBot User-agent için komutlar yer alır.
User-agent: YandexBot
Allow: /blog/
Disallow /deneme/
Bu örnekte Googlebot User-agent’ı için /blog/ URL path’inin crawl akışına dahil edilmemesi istenirken, YandexBot için /deneme/ URL path’inin crawl edilmemesi komutu gönderilir.
Txt dosyası oluşturmaya ve düzenlemeye izin veren herhangi bir editör aracılığıyla oluşturulabilecek robots.txt’de dikkat edilmesi gereken nokta; dosyanın adının mutlaka “robots”, uzantısının ise “.txt” olması ve UTF-8 karakter kodlaması ile kurgulanması gerektiğidir.
Arama motoru botlarının ilk anda göz attığı bir dosya olması itibariyle robots.txt’de bir yönerge niteliği taşıyan site haritasına yer vermek önemlidir.
Robots.txt’ye ekleyeceğimiz;
Sitemap: https://www.erentcolak.com.tr/sitemap.xml (Web sitesinin Sitemap’i)
satırı ile arama motoru botlarının site haritamıza ulaşmasına yardımcı olabiliriz.
Robots.txt, doğrudan site ana dizinine konumlandırılması gereken bir dosyadır.
Örneğin; www.erentcolak.com.tr‘nin robots.txt dosyasının sorunsuz çalışabilmesi adına www.erentcolak.com.tr/robots.txt şeklinde kurgulanması gerekir.
Oluşturmayı hedeflediğimiz robots.txt kurgusunu canlıya almadan önce Google’ın sunduğu Robots.txt Test Aracı’nda inceleyebilir, böylelikle olası hataları ya da eklemek istediğimiz farklı noktaları henüz robots.txt canlıda değilken tespit edebiliriz.
https://www.google.com/webmasters/tools/robots-testing-tool ile araca erişim sağladıktan sonra hangi web sitesi için test yapmak istediğimiz seçmemiz gerekir.
Google bu noktada eğer halihazırda Console doğrulamasını yapmadığımız bir web sitesi olma ihtimaline karşın “yeni bir mülk ekleme” seçeneği de sunuyor.
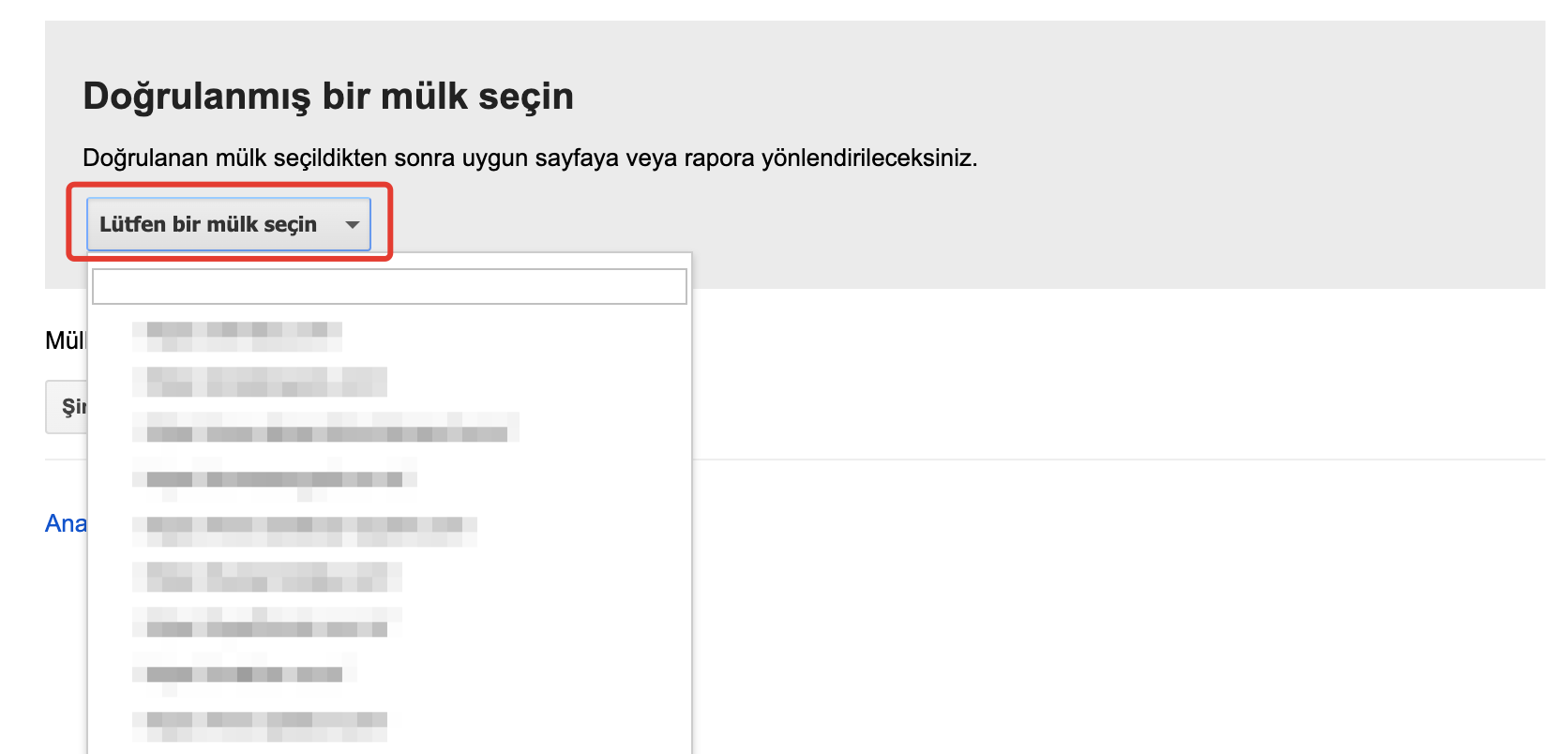
Web sitesi seçimi yaptıktan sonra karşımıza çıkan ekranda mevcuttaki robots.txt dosyamızı ve test alanını görebiliyoruz.
Bu ekranda robots.txt dosyamıza ekleme ya da çıkarma yapabilir, aldığımız değişimlerin etkilerini hemen altta yer alan test çubuğu aracılığıyla görebiliriz.
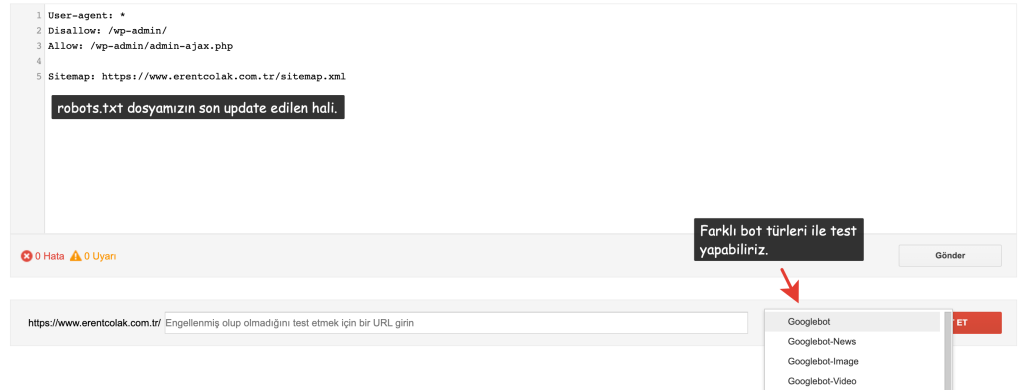
Örneğin; “seo” path’ine sahip URL’ler için robots.txt’ye Disallow: /seo/ satırı ekledik. Bu satırın işe yarayıp yaramadığını anlık olarak test ettikten sonra herhangi bir yazım hatası vb. durum varsa hızlıca düzenleyebilir ve sonrasında optimum robots.txt’yi canlıya alabiliriz.
Robots.txt test aracının dikkat çeken özelliklerinden biri farklı “spider” türleri ile test imkanı sunmasıdır. “Test” butonunun solunda yer alan alana tıklayarak farklı bot çeşitleri için test işlemi gerçekleştirebiliriz.
Eğer test sonucunda “Engellendi” çıktısını alıyorsak tettiğimiz URL oluşturduğumuz robots.txt kurgusu ile engelleniyor demektir. Fakat “Kabul Edildi” çıktısını alıyorsak arama motoru botları ilgili URL ya da URL’lerimize erişebiliyordur.
Robots.txt Test Aracıyla İlgili: https://support.google.com/webmasters/answer/6062598
Hayır, robots.txt kullanımı noktasında herhangi bir zorunluluk yoktur fakat robots.txt çoğu zaman crawl akışını yönetmek için en ideal yapı olması ile ön plana çıkar.
Web sitenizin robots.txt dosyası olmadığında da arama motoru botları web sayfalarınızı tarayarak dizine ekleyebilir.
Arama motoru botları tarafından crawl edilmesini istediğimiz URL’ler için robots.txt’de allow komutu kullanmamıza gerek yoktur.
Farklı tekniklerle aksi belirtilmediği takdirde (disallow, robots meta tag) takdirde arama motoru botları akış içerisinde yer alan web sayfalarımızı tarayacaktır.
Hayır, web sitesinin tek bir benzersiz robots.txt dosyası olmalıdır. Farklı bot türleri için crawl akışını bu robots.txt üzerindeki komutlarla düzenlemek gerekir.
Bir örnekle bakalım:
User-agent: Googlebot
Disallow: /deneme-path/
Disallow: *?deneme
User-agent: Bingbot
Disallow: /bing-path/
Birden fazla User-agent kullanarak crawl akışını farklı bot türleri için yönetebiliriz. Çoğu zaman buna ihtiyacımız olmaz aslında çünkü crawling’e dahil etmek istediğimiz sayfalar bot bazlı değişkenlik göstermez.
Belirli botlardan gelen request’leri tümüyle kapatıp sunucu tarafında bir kaynak optimizasyonuna gitmek istediğimizde ise ideal seçenektir.
Robots.txt bir web sayfasının erişim durumunu yani crawl akışı içerisine dahil edilip edilmeyeceğini belirlemek için kullanılırken robots meta tag, bir web sayfasının dizine eklenme durumunu (örneğin; bir web sayfası noindex,nofollow olarak tag’lenebilir) kontrol eder.
Robots meta tag’in arama motoru botları tarafından anlamlandırılması için web sayfasının taranması yani crawl akışında olması gerekir. Sayfa tarandıktan sonra botlar robots meta tag’deki yönergeleri dikkate alabilir.
Site haritası, botların akıştaki web sayfalarını keşfetmesini kolaylaştırır. Robots.txt’de Sitemap satırı ile site haritasına yer vererek arama motoru botlarının bu yapıyı bulma sürecini kısaltabilir.
Diğer taraftan robots.txt’de site haritasına yer vermesek de Google site haritasını keşfeder. Doğrudan Search Console’dan da gönderiyor ve teslim ediyoruz. Aynı işlem günün sonunda.
Dolayısıyla robots.txt’de sitemap’in konumlandırılması tercih meselesidir. Burada tercihim, site haritasının robots.txt içerisinde yer alması.
Bir içeriğin daha sonuna geldik. Umarım amacına ulaşan ve sizler için fayda üreten bir içerik olmuştur. Geri bildirimlerinizi mutlaka bekliyorum.
Organik Büyüme İçin İlk Adımı Atın!
Web sitenizin ve markanızın potansiyelini ortaya çıkarmak, organik görünürlüğünüzü artırmak ve doğru hedef kitleye ulaşmak için şimdi iletişime geçin. İhtiyaçlarınıza özel çözümler sunmak için buradayım!


Eren Talha Çolak
SEO & Organic Growth Danışmanı
Merhaba, ben Eren. 2017 yılında adım attığım ve aradan geçen süre içerisinde SEO'nun yanı sıra dijital pazarlamanın tüm çalışma alanlarını deneyimleme fırsatı bulduğum bu dünyada, danışmanlık verdiğim tüm markalarda istisnasız organik büyüme ve katma değer sağlama hedeflerine hizmet edecek detay stratejiler ile ilerliyor; bu bakış açısının yarattığı farkı veriler ile somutlaştırarak ölçümlenebilir sonuçlar ortaya koyuyorum.
SEO & Organic Growth Blog
Dijital dünyada organik büyüme stratejileri ve SEO teknikleri üzerine teorinin yanı sıra deneyim ve gözlemlerimi paylaştığım blog içeriklerini inceleyerek dijital varlığınızı güçlendirmek ve uygulama becerilerinizi geliştirmek için ihtiyacınız olan ipuçlarına ulaşabilirsiniz.
 Backlink Gap Analizi: Off-Page'de Fırsatları Keşfetmek ve Otoriteye Dönüştürmek
Backlink Gap Analizi: Off-Page'de Fırsatları Keşfetmek ve Otoriteye Dönüştürmek
Bu içerikte, Backlink Gap analizi ile rakiplerinizin yer aldığı ancak sizin görünür olmadığınız mecraları nasıl tespit e...
21 Haziran 2025
Okuma Süresi: 18 Dakika
Orphan Page (Yetim Sayfa) Nedir? Nasıl Tespit Edilir?
23 Mayıs 2025
Okuma Süresi: 26 Dakika
© 2025 - Eren Talha ÇOLAK
Yorum Yaz